

As a part of right now’s Worldwide Supercomputing 2021 (ISC) bulletins, Intel is showcasing that will probably be launching a model of its upcoming Sapphire Rapids (SPR) Xeon Scalable processor with high-bandwidth reminiscence (HBM). This model of SPR-HBM will come later in 2022, after the principle launch of Sapphire Rapids, and Intel has acknowledged that will probably be a part of its common availability providing to all, relatively than a vendor-specific implementation.
Hitting a Reminiscence Bandwidth Restrict
As core counts have elevated within the server processor area, the designers of those processors have to make sure that there’s sufficient information for the cores to allow peak efficiency. This implies growing giant quick caches per core so sufficient information is shut by at excessive pace, there are excessive bandwidth interconnects contained in the processor to shuttle information round, and there’s sufficient principal reminiscence bandwidth from information shops positioned off the processor.

Our Ice Lake Xeon Evaluation system with 32 DDR4-3200 Slots
Right here at AnandTech, now we have been asking processor distributors about this final level, about principal reminiscence, for some time. There’s solely a lot bandwidth that may be achieved by frequently including DDR4 (and shortly to be DDR5) reminiscence channels. Present eight-channel DDR4-3200 reminiscence designs, for instance, have a theoretical most of 204.8 gigabytes per second, which pales compared to GPUs which quote 1000 gigabytes per second or extra. GPUs are in a position to obtain increased bandwidths as a result of they use GDDR, soldered onto the board, which permits for tighter tolerances on the expense of a modular design. Only a few principal processors for servers have ever had principal reminiscence be built-in at such a stage.

Intel Xeon Phi ‘KNL’ with 8 MCDRAM Pads in 2015
One of many processors that was once constructed with built-in reminiscence was Intel’s Xeon Phi, a product discontinued a few years in the past. The idea of the Xeon Phi design was a number of vector compute, managed by as much as 72 primary cores, however paired with 8-16 GB of on-board ‘MCDRAM’, related through 4-8 on-board chiplets within the package deal. This allowed for 400 gigabytes per second of cache or addressable reminiscence, paired with 384 GB of principal reminiscence at 102 gigabytes per second. Nevertheless, since Xeon Phi was discontinued, no principal server processor (not less than for x86) introduced to the general public has had this kind of configuration.
New Sapphire Rapids with Excessive-Bandwidth Reminiscence
Till subsequent yr, that’s. Intel’s new Sapphire Rapids Xeon Scalable with Excessive-Bandwidth Reminiscence (SPR-HBM) might be coming to market. Fairly than cover it away to be used with one explicit hyperscaler, Intel has acknowledged to AnandTech that they’re dedicated to creating HBM-enabled Sapphire Rapids obtainable to all enterprise prospects and server distributors as effectively. These variations will come out after the principle Sapphire Rapids launch, and entertain some attention-grabbing configurations. We perceive that this implies SPR-HBM might be obtainable in a socketed configuration.

Intel states that SPR-HBM can be utilized with normal DDR5, providing an extra tier in reminiscence caching. The HBM could be addressed straight or left as an automated cache we perceive, which might be similar to how Intel’s Xeon Phi processors might entry their excessive bandwidth reminiscence.
Alternatively, SPR-HBM can work with none DDR5 in any respect. This reduces the bodily footprint of the processor, permitting for a denser design in compute-dense servers that don’t rely a lot on reminiscence capability (these prospects have been already asking for quad-channel design optimizations anyway).
The quantity of reminiscence was not disclosed, nor the bandwidth or the expertise. On the very least, we count on the equal of as much as 8-Hello stacks of HBM2e, as much as 16GB every, with 1-4 stacks onboard resulting in 64 GB of HBM. At a theoretical high pace of 460 GB/s per stack, this may imply 1840 GB/s of bandwidth, though we will think about one thing extra akin to 1 TB/s for yield and energy which might nonetheless give a sizeable uplift. Relying on demand, Intel might fill out completely different variations of the reminiscence into completely different processor choices.
One of many key components to contemplate right here is that on-package reminiscence can have an related energy price throughout the package deal. So for each watt that the HBM requires contained in the package deal, that’s one much less watt for computational efficiency on the CPU cores. That being mentioned, server processors typically don’t push the boundaries on peak frequencies, as a substitute choosing a extra environment friendly energy/frequency level and scaling the cores. Nevertheless HBM on this regard is a tradeoff – if HBM have been to take 10-20W per stack, 4 stacks would simply eat into the ability price range for the processor (and that energy price range needs to be managed with extra controllers and energy supply, including complexity and value).
One factor that was complicated about Intel’s presentation, and I requested about this however my query was ignored throughout the digital briefing, is that Intel retains placing out completely different package deal pictures of Sapphire Rapids. Within the briefing deck for this announcement, there was already two variants. The one above (which truly appears to be like like an elongated Xe-HP package deal that somebody put a emblem on) and this one (which is extra sq. and has completely different notches):

There have been some unconfirmed leaks on-line showcasing SPR in a 3rd completely different package deal, making all of it complicated.
Sapphire Rapids: What We Know
Intel has been teasing Sapphire Rapids for nearly two years because the successor to its Ice Lake Xeon Scalable household of processors. Constructed on 10nm Enhanced SuperFin, SPR might be Intel’s first processors to make use of DDR5 reminiscence, have PCIe 5 connectivity, and assist CXL 1.1 for next-generation connections. Additionally on reminiscence, Intel has acknowledged that Sapphire Rapids will assist Crow Cross, the subsequent technology of Intel Optane reminiscence.
For core expertise, Intel (re)confirmed that Sapphire Rapids might be utilizing Golden Cove cores as a part of its design. Golden Cove might be central to Intel’s Alder Lake shopper processor later this yr, nonetheless Intel was fast to level out that Sapphire Rapids will supply a ‘server-optimized’ configuration of the core. Intel has executed this prior to now with each its Skylake Xeon and Ice Lake Xeon processors whereby the server variant typically has a special L2/L3 cache construction than the patron processors, in addition to a special interconnect (ring vs mesh, mesh on servers).
Sapphire Rapids would be the core processor on the coronary heart of the Aurora supercomputer at Argonne Nationwide Labs, the place two SPR processors might be paired with six Intel Ponte Vecchio accelerators, which can even be new to the market. In the present day’s announcement confirms that Aurora might be utilizing the SPR-HBM model of Sapphire Rapids.
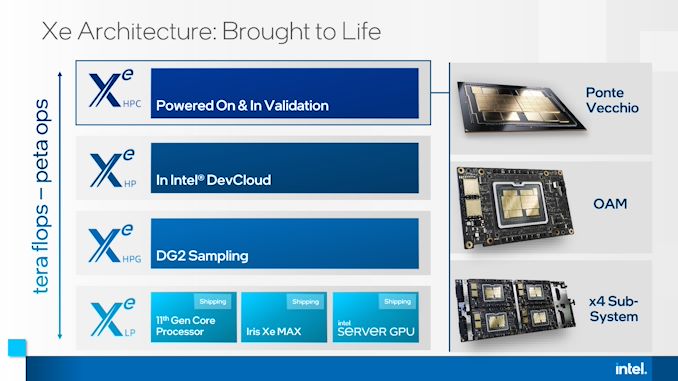
As a part of this announcement right now, Intel additionally acknowledged that Ponte Vecchio might be broadly obtainable, in OAM and 4x dense type elements:
Sapphire Rapids can even be the primary Intel processors to assist Superior Matrix Extensions (AMX), which we perceive to assist speed up matrix heavy workflows akin to machine studying alongside additionally having BFloat16 assist. This might be paired with updates to Intel’s DL Enhance software program and OneAPI assist. As Intel processors are nonetheless highly regarded for machine studying, particularly coaching, Intel desires to capitalize on any future development on this market with Sapphire Rapids. SPR can even be up to date with Intel’s newest {hardware} primarily based safety.
It’s extremely anticipated that Sapphire Rapids can even be Intel’s first multi compute-die Xeon the place the silicon is designed to be built-in (we’re not counting Cascade Lake-AP Hybrids), and there are unconfirmed leaks to recommend that is the case, nonetheless nothing that Intel has but verified.

The Aurora supercomputer is anticipated to be delivered by the top of 2021, and is anticipated to not solely be the primary official deployment of Sapphire Rapids, but additionally SPR-HBM. We count on a full launch of the platform someday within the first half of 2022, with common availability quickly after. The precise launch of SPR-HBM past HPC workloads is unknown, nonetheless given these time frames, This fall 2022 appears pretty cheap relying on how aggressive Intel desires to assault the launch in mild of any competitors from different x86 distributors or Arm distributors. Even with SPR-HBM being supplied to everybody, Intel might determine to prioritize key HPC prospects over common availability.






{kind=link}